LLaMA-Factory
综合介绍
LLaMA Factory 是一个开源项目,旨在让上百种大语言模型(LLM)和视觉语言模型(VLM)的微调过程变得简单高效。它集成了一系列先进的训练方法和优化技术,将复杂的模型训练流程整合到一个统一的框架中。用户无论背景如何,都可以通过该项目提供的网页用户界面(Web UI)或命令行工具,轻松地对模型进行(继续)预训练、监督微调、奖励模型训练和强化学习等任务。该项目不仅支持 LoRA、QLoRA 等低资源微调技术,还实现了 FlashAttention-2、vLLM 等加速算法,显著降低了微调的技术门槛和硬件成本,让开发者和研究人员可以更专注于特定任务的模型定制与能力开发。
功能列表
- 支持多种模型: 全面支持 LLaMA、Mistral、Qwen、Gemma、DeepSeek、ChatGLM 等超过100种主流的语言和视觉模型。
- 集成多种训练方法: 支持(连续)预训练、监督微调(SFT)、奖励建模(RM)、近端策略优化(PPO)、直接偏好优化(DPO)等多种训练方式。
- 高效的资源管理: 通过LoRA和多精度QLoRA(2/3/4/5/6/8位)等技术,支持在消费级硬件上进行模型微调。
- 先进的优化算法: 集成了GaLore、DoRA、LongLoRA等前沿算法,提升训练效率和模型性能。
- 实用的训练技巧: 内置FlashAttention-2、Unsloth等加速库,并支持RoPE扩展上下文长度,优化模型训练速度和内存占用。
- 广泛的任务支持: 能够应对多轮对话、工具使用、图像理解、视频识别、音频理解等多种复杂任务。
- 易用的监控和部署: 提供LlamaBoard、TensorBoard等多种实验监控工具,并支持通过OpenAI风格的API和Gradio界面进行快速部署和推理。
- 零代码网页界面: 提供名为“LLaMA Board”的网页用户界面(Web UI),用户可以通过点击操作完成模型的微调、评估和导出,极大地降低了使用门槛。
使用帮助
LLaMA Factory 提供了多种安装和使用方式,以适应不同用户和平台的需求。
安装
安装是使用 LLaMA Factory 的第一步,也是必须完成的步骤。
1. 从源码安装 (推荐)
这是最常见的安装方式,可以确保获取最新的功能。
# 克隆项目仓库
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
# 进入项目目录
cd LLaMA-Factory
# 安装核心依赖
pip install -e ".[torch,metrics]" --no-build-isolation
```项目中还提供了额外的依赖选项,可根据需求安装,例如 `bitsandbytes` 用于QLoRA,`vllm` 用于加速推理等。
**2. 使用 Docker 镜像**
对于希望在隔离环境中运行的用户,Docker 是一个很好的选择。官方提供了预构建的镜像。
```bash
# 运行最新的Docker镜像,并挂载所有GPU
docker run -it --rm --gpus=all --ipc=host hiyouga/llamafactory:latest
该镜像基于Ubuntu 22.04,并预装了CUDA、PyTorch和FlashAttention等核心库。
3. Windows 用户特别说明
Windows 用户需要手动安装特定版本的 PyTorch 以支持 GPU。同时,若要使用 QLoRA 功能,需要安装适配 Windows 的 bitsandbytes 库。
数据准备
LLaMA Factory 支持多种格式的数据集,包括 Alpaca 和 ShareGPT 格式。 用户可以使用 Hugging Face Hub 上的公开数据集,也可以加载本地磁盘上的数据文件。
关键步骤是修改位于 data/dataset_info.json 的配置文件,将你的自定义数据集信息添加进去,这样框架才能识别并加载它。
快速上手
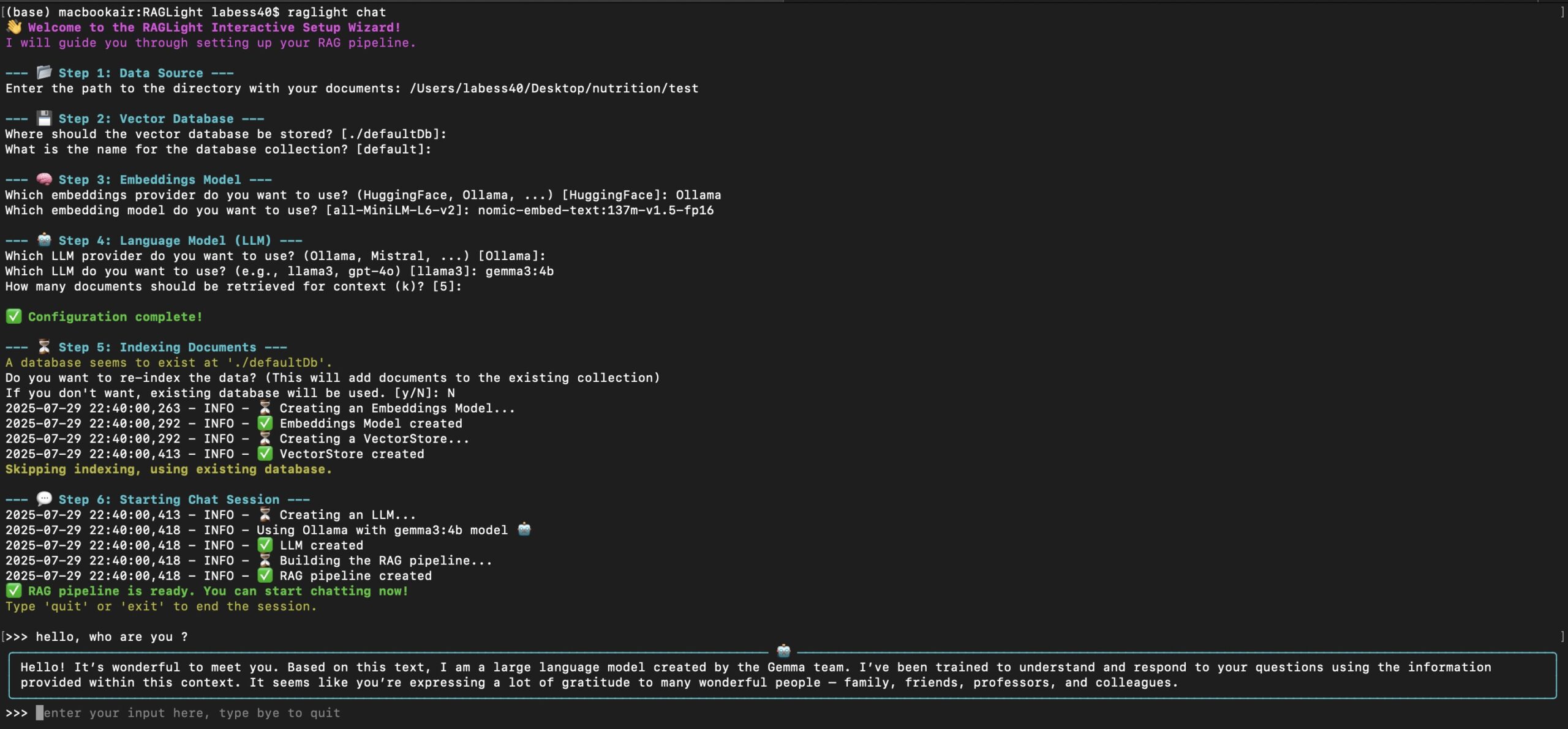
LLaMA Factory 的设计哲学是易用性,通过 llamafactory-cli 命令行工具或 LLaMA Board 网页界面,可以快速启动训练任务。
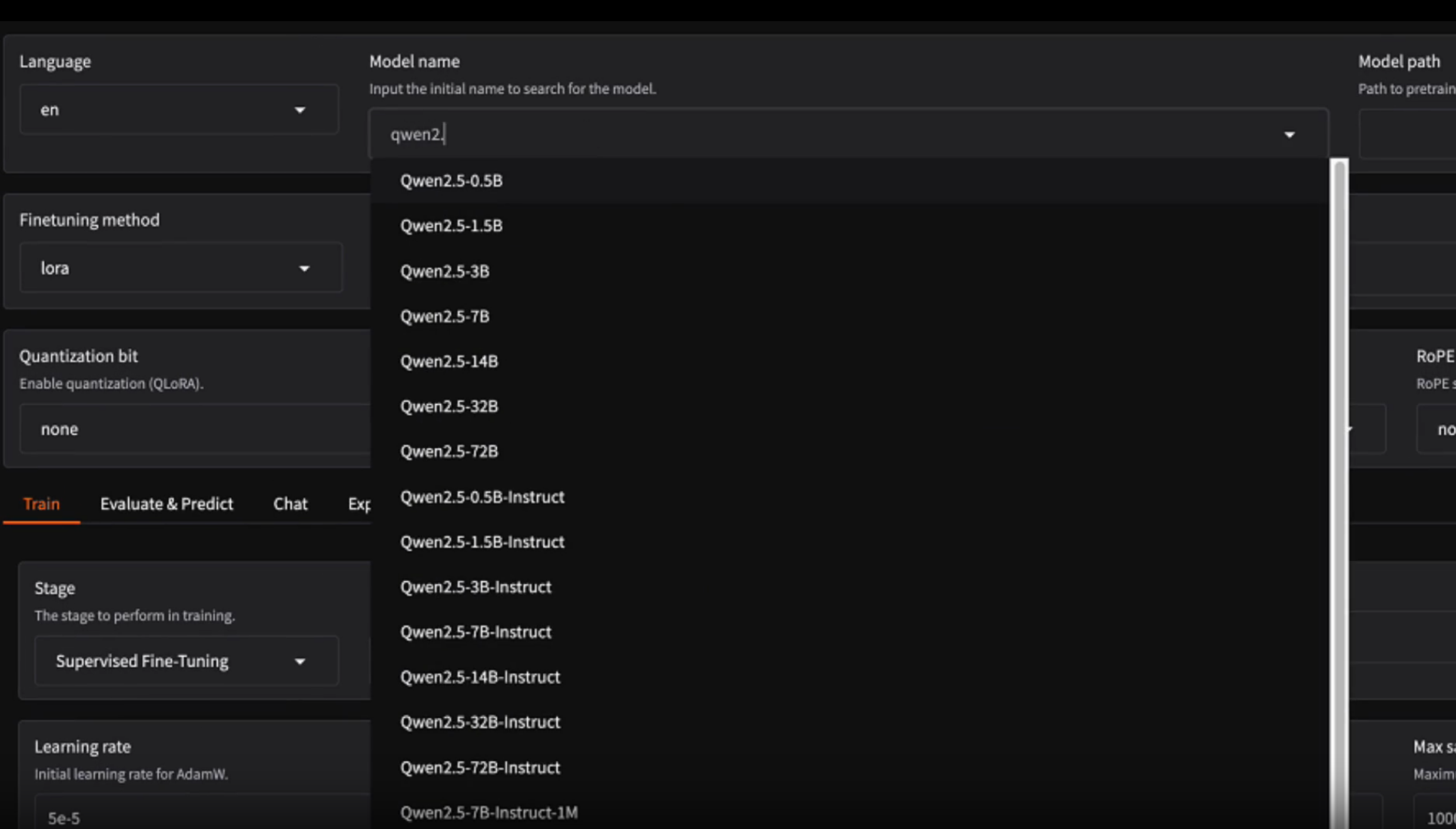
1. 使用网页界面 (LLaMA Board)
对于初学者或偏好图形界面的用户,这是最简单的方式。
# 启动Web UI
llamafactory-cli webui
执行该命令后,会生成一个本地网址。在浏览器中打开该网址,即可看到一个可视化的操作界面。 你可以在页面上通过下拉菜单和输入框选择模型、数据集、微调方法和各项超参数,然后点击开始按钮即可启动训练。
2. 使用命令行
对于熟悉命令行的用户,可以使用 YAML 配置文件来定义训练任务,这种方式更适合自动化和批量实验。
项目 examples 目录下提供了大量预设的配置文件,覆盖了不同模型和微调方法的组合。
以下是一个使用 LoRA 微调 Llama3-8B 模型的示例流程:
- 训练 (Train):
llamafactory-cli train examples/train_lora/llama3_lora_sft.yaml - 评估与对话 (Chat): 训练完成后,可以立即加载微调后的模型进行对话测试。
llamafactory-cli chat examples/inference/llama3_lora_sft.yaml - 导出模型 (Export): 对于 LoRA 微调,需要将训练得到的适配器权重(adapter)与基础模型合并,才能得到一个独立完整的微调模型。
llamafactory-cli export examples/merge_lora/llama3_lora_sft.yaml
API 部署
LLaMA Factory 支持使用 vLLM 作为后端,部署为与 OpenAI API 格式兼容的服务,方便集成到现有应用中。
# 启动API服务
llamafactory-cli api examples/inference/llama3.yaml --infer_backend vllm
应用场景
- 学术研究研究人员可以利用 LLaMA Factory 快速验证新的模型优化算法、探索不同微调技术对模型性能的影响,或针对特定的学术数据集(如医疗、法律)训练专用模型。
- 定制化智能客服企业可以利用自身的客户对话数据,通过监督微调(SFT)训练出更懂业务、能准确回答客户问题的智能客服机器人,提升服务质量和效率。
- 个人AI助手开发者可以收集自己的写作风格、编程习惯或邮件回复等数据,对模型进行微调,打造一个能模仿自己风格、辅助完成日常工作的个性化AI助手。
- 特定领域内容生成内容创作者,如小说家或营销文案撰写人,可以使用特定的语料库微调模型,使其能够生成符合特定风格或领域要求的文本内容,辅助创作过程。
QA
- LLaMA Factory 对硬件有什么要求?硬件需求取决于要微调的模型大小和微调方法。 使用全参数微调一个 70亿(7B)参数的模型大约需要 120GB 的显存;而使用 4-bit QLoRA 技术,则能将需求降低到约 6GB 显存,一张消费级显卡(如 RTX 3090/4090)即可满足要求。
- 我可以使用自己的数据集吗?完全可以。 你需要将你的数据集整理成项目支持的JSON格式(如Alpaca格式),然后修改
data/dataset_info.json文件,将你的数据集信息注册进去,即可在训练时选择使用。 - 微调和预训练有什么区别?预训练(Pre-training)是指在一个非常大规模、通用的文本数据上从零开始训练模型,使其掌握语言的基础规律,这个过程计算成本极高。微调(Fine-tuning)则是在预训练好的模型基础上,使用一个规模相对较小、针对特定任务的数据集进行进一步训练,让模型适应特定领域或任务,成本远低于预训练。
- 什么是 LoRA 和 QLoRA?LoRA(Low-Rank Adaptation)是一种参数高效的微调方法,它通过训练一个微小的“适配器”来调整模型行为,而不是更新模型的所有参数,从而大大降低了显存需求。QLoRA 则是 LoRA 的进一步优化,它将模型参数进行“量化”(降低精度),从而在训练时进一步减少显存占用。